Feature Engineering in Health Data: ChatGPT-4o vs Classical ML
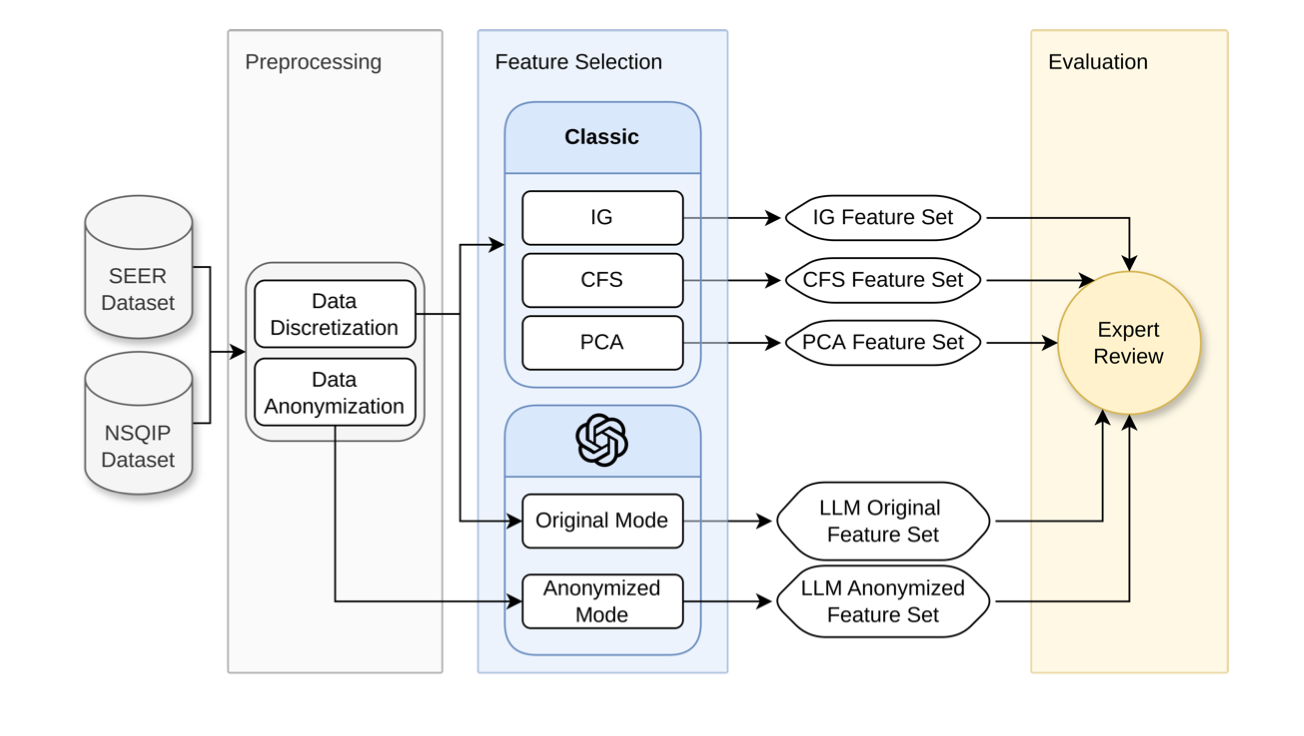
Machine learning (ML) is demonstrating remarkable success in various healthcare applications. The success of ML in healthcare is inherently linked to the rigorous process of feature engineering and feature selection, which truly forms the backbone of ML model development. This study investigates the role of a well-known large language model (LLM), the ChatGPT-4o, in feature selection and classification processes for healthcare data, focusing on the explainability of ML. The performance of ChatGPT-4o is evaluated and compared to traditional ML methods—such as information gain (IG), correlation-based feature selection (CFS), and principal component analysis (PCA) for identifying relevant features in predictive modeling. This comparison is conducted using two widely recognized healthcare datasets, SEER and NSQIP. After evaluating the features selected by classical ML methods and LLMs through expert review, the results indicate that while ChatGPT-4o aligns closely with expert evaluations and effectively provides contextual information on healthcare datasets, traditional ML methods such as IG, CFS, and PCA outperform in systematic feature ranking due to their structured and data-driven nature. Furthermore, anonymization did not significantly affect the feature selection process, highlighting the robustness of ChatGPT-4o under privacy-preserving conditions. ChatGPT-4o's strength lies in complementing these methods by providing interpretability and facilitating exploratory analysis, rather than serving as a standalone solution for precise feature ranking.
Paper: Download PDF